nanochat-sec: $150, 6 Hours, and a Model That Hallucinates Log4Shell
How I adapted nanochat for security vulnerability work, what the training logs actually showed, and where the model broke
![]()
Table of Contents
- Recap: Where the Last Post Left Off
- What Is nanochat, and Why Fork It for Security?
- Infrastructure: Prime Intellect and Non-Spot GPUs
- The Security Data Mix
- SFT: Supervised Fine-Tuning
- RL: Reinforcement Learning for Vulnerability Detection
- What Broke During Interactive Testing
- Why Those Failures Happened
- The Checkpoint Tradeoff
- Closing Notes
Recap: Where the Last Post Left Off
In my previous post, I fine-tuned a 7B parameter model on ~4,000 scraped HackerOne reports using QLoRA, merged the adapter, quantized the result to GGUF, and ran it locally via Ollama. The model learned the output format perfectly—96% section adherence—but when I actually read the outputs, the quality was—well—nonsense. My scraper had been falling back to the same HTML meta description for multiple fields, so the model was essentially mirroring repetitive training patterns. The metrics looked great while the real analytical improvement was minimal.
Data quality is the whole game. If your dataset has repetition or leakage, the model will happily learn it, and your metrics will reward pattern copying.
This post picks up from that lesson. I trained a model from scratch using Andrej Karpathy’s nanochat framework, added a security specialization layer on top, and pushed the whole thing through SFT and then RL on rented GPUs.
What Is nanochat, and Why Fork It for Security?
nanochat is Karpathy’s small-model training stack—a minimal but complete pipeline for training language models from scratch, running SFT to teach chat behavior, and then applying RL to optimize for specific task objectives. It handles tokenizer training, base model pretraining, chat fine-tuning, and evaluation in one integrated codebase.
I forked it as nanochat-sec because it gave me control over every stage of training, from the raw pretraining corpus through to the final RL reward function. I could build a smaller model from scratch and shape its entire training trajectory toward security work.
A model trained from scratch at this scale won’t match the raw capability of a pretrained 7B. It does let you understand exactly what the model learned, where, and why. That understanding is what I was after.
The final model configuration:
1
2
3
4
5
6
7
8
9
10
11
12
13
Model config:
{
"sequence_len": 2048,
"vocab_size": 32768,
"n_layer": 26,
"n_head": 13,
"n_kv_head": 13,
"n_embd": 1664,
"window_pattern": "SSSL"
}
Parameter counts:
total: 1,681,790,292
So the entire experiment sat on a ~1.68B parameter model. That constraint matters for every outcome below.
Infrastructure: Prime Intellect and Non-Spot GPUs
I ran this on Prime Intellect using 8x NVIDIA H100 80GB HBM3 GPUs. The full pipeline—tokenizer training, base pretraining, SFT, RL, and evaluation—took about 6 hours end-to-end (roughly 5 hours of actual training, the rest in evals and dataset loading) and cost around $150.
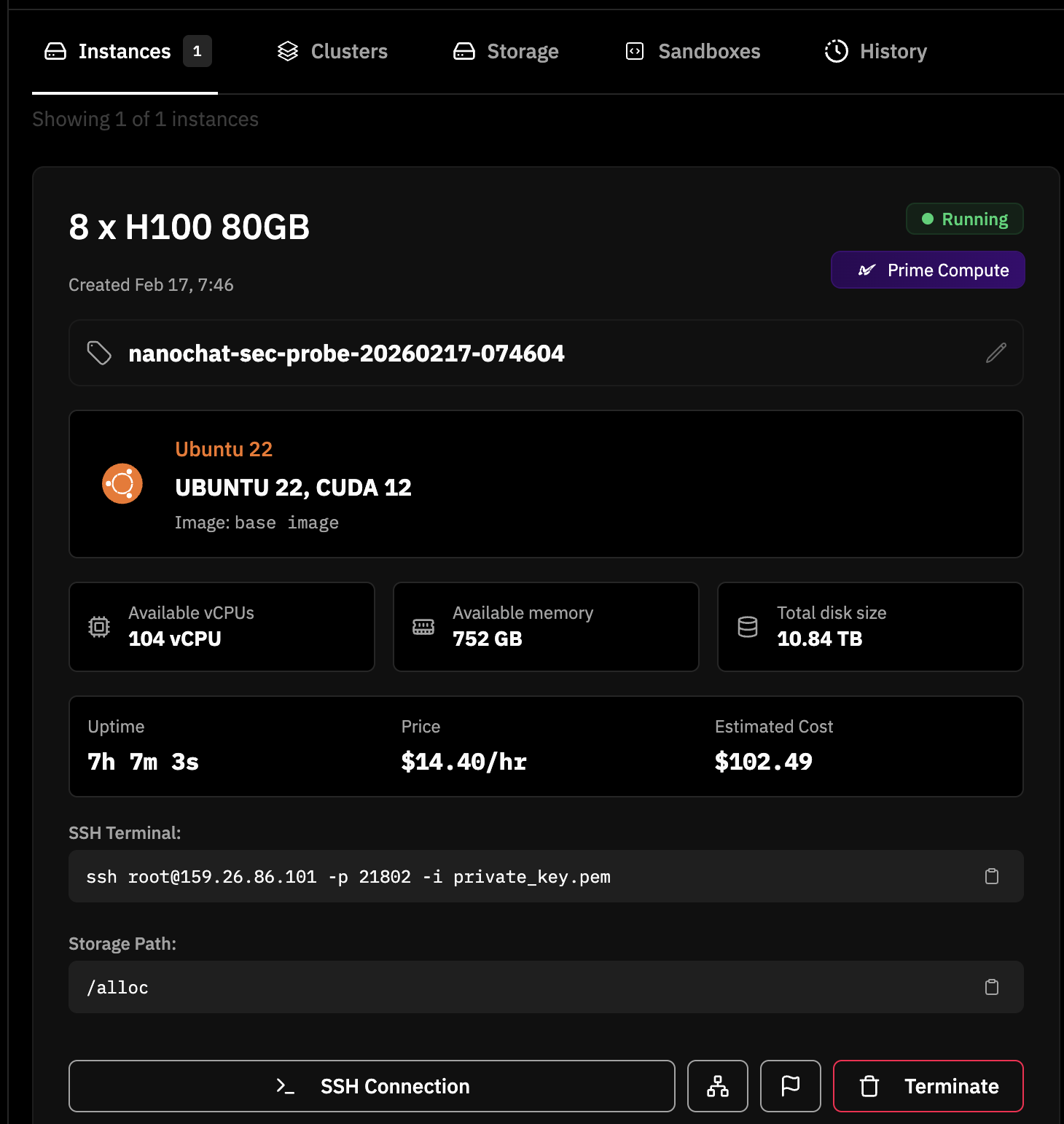
One lesson I learned the expensive way: I initially spun up a spot instance without really understanding what “spot” meant. About 4 hours into the run, the spot did exactly what spot is supposed to do—gave back the resources and shutdown. The run and all the artifacts went with it. After that, I patched the provisioning logic to hard-filter for non-spot offers only:
1
2
3
4
resources = data.get("gpu_resources", [])
def is_non_spot(resource):
return resource.get("is_spot") is False
And the launcher script fails immediately if non-spot capacity isn’t available:
1
2
3
4
if [ -z "${RESOURCE_STATUS:-}" ] || [ "$RESOURCE_STATUS" != "ok" ] || [ -z "${RESOURCE_ID:-}" ]; then
echo "ERROR: No non-spot availability found for ${GPU_COUNT}x ${GPU_TYPE}."
exit 1
fi
The Security Data Mix
Data quality wrecked the last run, so I spent more time on dataset selection this time. I assembled a mixture of publicly available datasets, each serving a specific purpose in the training blend.
1
2
3
4
5
6
7
8
9
10
train_dataset = TaskMixture([
SmolTalk(split="train", stop=150000),
TrendyolCybersec(),
FenrirCybersec(),
CVERecords(split="train"),
GSM8K(subset="main", split="train"),
GSM8K(subset="main", split="train"),
CustomJSON(filepath=identity_conversations_filepath),
CustomJSON(filepath=identity_conversations_filepath),
])
Three of these datasets already existed in upstream nanochat. The security ones were new.
Already in nanochat:
- SmolTalk (150K examples, reduced from the original 460K): Conversational continuity and follow-up handling. I shrunk it to make room for security data.
- GSM8K (doubled): Lightweight reasoning anchor so the model doesn’t lose basic problem-solving capability during security-heavy SFT.
- Identity conversations (doubled): Persona consistency so the model identifies itself coherently. In nanochat-sec these were rewritten for a security researcher persona.
Introduced in nanochat-sec:
- TrendyolCybersec (~53K): Broad security Q&A across 200+ security domains. General defensive security coverage.
- FenrirCybersec (~84K): OWASP/MITRE/NIST/CIS structured causal analyses. More rigorous and structured than Trendyol.
- CVERecords (~244K train, ~53K test): CVE vulnerability reports, split by year—train on CVE years ≤ 2023, test on ≥ 2024. This gave me a temporally clean evaluation boundary.
How the security data was shaped
All three security datasets were wrapped as single-turn supervision in system → user → assistant format:
1
2
3
4
5
messages = [
{"role": "system", "content": _safe_text(row.get("system"))},
{"role": "user", "content": _safe_text(row.get("user"))},
{"role": "assistant", "content": assistant_text},
]
For long responses—Fenrir in particular had entries exceeding 37K characters—I applied sentence-aware truncation at 6,000 characters as a practical heuristic to reduce context overflow risk against the model’s 2048-token window. The truncation rates from the training log show how this played out:
1
2
3
4
TrendyolCybersec: ~0/53201 examples truncated (~0.0%)
FenrirCybersec: ~4196/83920 examples truncated (~5.0%)
CVERecords(train): ~488/244133 examples truncated (~0.2%)
CVERecords(test): ~319/53308 examples truncated (~0.6%)
Fenrir carried the highest truncation pressure—5% of its examples were cut—which is the price of structured security analyses that try to cover root cause, impact, MITRE mappings, and remediation in a single response.
The CVE year-based split
One thing I wanted to get right this time was evaluation integrity. The CVE dataset doesn’t ship with a predefined train/test split, so I built one from the CVE IDs themselves:
1
2
3
4
CVE_YEAR_RE = re.compile(r'CVE-(\d{4})-')
# Train: CVE year <= 2023
# Test: CVE year >= 2024
This is a temporal split. The model never sees 2024+ CVEs during training, so the test set measures generalization to genuinely new vulnerability disclosures.
The multi-turn caveat
There was one unplanned data issue. Identity conversation generation depended on an OPENROUTER_API_KEY for synthetic multi-turn chat creation. In this run, that key wasn’t set, so the pipeline fell back to a minimal hardcoded set:
1
2
WARNING: OPENROUTER_API_KEY not set. Creating minimal fallback identity conversations.
Created fallback identity file with 5 conversations
Five two-turn identity conversations. That meant the security supervision was strong, but identity-style multi-turn signal was weak. The model could answer security questions well in a single turn but had weak pressure to maintain persona consistency across longer conversations.
SFT: Supervised Fine-Tuning
SFT started from the base pretrained checkpoint (step 7,226, after ~163 minutes of pretraining on 7.6 billion tokens) and ran for 682 steps—one full epoch through the mixed dataset.
The loss curve during SFT dropped from an initial validation BPB (bits per byte—how many bits the model needs to predict each byte of text, lower means the model is less surprised by what it sees) of 1.0165 down to 0.3409:
1
2
3
4
5
6
Step 00000 | Validation bpb: 1.0165
step 00001 (0.17%) | loss: 1.315025
step 00010 (1.47%) | loss: 1.497617
...
step 00682 (100.01%) | loss: 0.740981
Step 00682 | Validation bpb: 0.3409
The SFT stage completed in about 9.4 minutes. After SFT, the model was evaluated on the custom VulnDetection benchmark—a binary vulnerability detection task where the model must answer #### Yes or #### No to whether a code snippet contains a vulnerability:
1
VulnDetection accuracy: 50.91%
That’s essentially coin-flip on the vulnerability detection task. SFT taught the model the format and gave it security vocabulary. Vulnerability classification accuracy stayed at coin-flip. RL is supposed to push that number up.
RL: Reinforcement Learning for Vulnerability Detection
The RL stage took the SFT checkpoint and optimized it against a binary reward signal: does the model correctly classify whether code is vulnerable? Concretely, the RL script loads the SFT checkpoint as its starting point (load_model("sft", ...)), so RL behavior in this run is a post-SFT shift, not an independent model lineage.
The reward function
The reward is intentionally simple—binary correctness:
1
2
def reward(self, conversation, assistant_response):
return float(self.evaluate(conversation, assistant_response))
The model gets 1.0 for a correct #### Yes or #### No answer and 0.0 for anything else. This follows the same pattern nanochat uses for GSM8K math: parse the final answer, check it, return a binary score.
Training dynamics
RL ran for 465 steps. The early steps show the model starting from near-random on the task:
1
2
Step 0 | Pass@1: 0.0300, Pass@2: 0.1750, ... Pass@8: 0.4300
Step 0/465 | Average reward: 0.05078125
Pass@k means: give the model k attempts at the same problem, did it get it right at least once? Pass@1 is the strictest—one shot, did it nail it? Pass@8 is more forgiving—eight tries, did any of them work? Here, Pass@1 started at 3%—the model almost never gets it right on its first try. But within 120 steps, reward climbed substantially:
1
2
Step 120 | Pass@1: 0.5725, ... Pass@8: 0.5850
Step 120/465 | Average reward: 0.625
Here’s where things got interesting. By step 120, the policy gradient loss had collapsed to near-zero, and it stayed there for the rest of training:
1
2
3
4
5
Step 153/465 | Example step 0 | Pass 0 | loss: -0.000000 | Average reward: 1.0
Step 153/465 | Example step 0 | Pass 1 | loss: -0.000000 | Average reward: 1.0
Step 153/465 | Example step 1 | Pass 0 | loss: -0.000000 | Average reward: 1.0
Step 153/465 | Example step 1 | Pass 1 | loss: -0.000000 | Average reward: 1.0
Step 153/465 | Average reward: 0.5625
At first I thought the model was stuck. In this RL setup, it’s expected. Reward is binary and advantages are mean-centered within each batch (advantage = reward - mean(reward_batch)). When a batch is mostly all-correct or all-wrong, the advantages are near zero, which makes the policy gradient loss near zero too. The model is still learning; average reward and Pass@k are the right signals to watch.
The actual progress metrics are average reward and Pass@k. Here’s the trajectory across training:
| Step | Pass@1 | Average Reward |
|---|---|---|
| 0 | 0.030 | 0.051 |
| 120 | 0.573 | 0.625 |
| 240 | 0.638 | 0.625 |
| 300 | 0.650 | 0.688 |
| 360 | 0.593 | 0.625 |
| 420 | 0.553 | 0.496 |
| 464 | — | 0.563 |
Pass@1 peaked around step 300 at 65%, then drifted back down. Average reward plateaued in the 0.5–0.7 range. The model improved at the narrow task but hit a ceiling, and the later steps show some regression—a pattern consistent with reward hacking or forgetting on a binary objective.
The RL checkpoint was saved at step 464:
1
2
Saved model parameters to: .../chatrl_checkpoints/d26/model_000464.pt
Training complete: 2026-02-17 21:55:16 UTC
Post-RL VulnDetection accuracy: 49.95%—slightly below the SFT checkpoint’s 50.91%. Important comparison note: Pass@k in this section comes from generative sampling inside the RL loop, while VulnDetection accuracy in chat evaluation is a separate categorical/logit benchmark (VulnDetectionMC). Treat them as directional signals, not one-to-one equivalents. More on why below.
What Broke During Interactive Testing
When I pulled the artifacts locally and started interactive testing, I was like—wait, what the heck is even this.
1) Repetitive loop output
Prompting the RL checkpoint for open-ended security analysis produced degenerate loops:
1
2
3
4
Assistant: ### Threat Model
### Threat Model
### Threat Model
...
The model was stuck in a repetition loop—it generated a heading and kept generating the same heading. No content followed. This made the model unusable for any analyst workflow that requires coherent multi-paragraph output.
2) CVE hallucinations with confident tone
I tested with CVE-2021-44228 (Log4Shell)—one of the most well-known CVEs in recent years. The model produced fluent, confident, and completely wrong answers:
1
Assistant: ...root cause is a vulnerability in the libssh library...
And in another run:
1
Assistant: CVE-2021-44228 is a vulnerability in the Linux kernel...
Log4Shell is a JNDI injection vulnerability in Apache Log4j. The model attributed it to libssh in one response and the Linux kernel in another. Both answers were written in the same polished, authoritative tone that a correct answer would use. That’s the dangerous part—the confidence doesn’t correlate with correctness.
3) Special token leakage
Some responses ended with raw special tokens leaking into user-visible output:
1
<|assistant_end|>
This is a tokenization/generation artifact. The model should stop at the end-of-turn token. A minor formatting issue compared to the hallucinations, but it signals that the generation boundaries aren’t clean.
Why Those Failures Happened
Three interconnected causes explain most of what went wrong.
1) Objective mismatch between RL and open-ended chat
The RL reward function optimized for binary vulnerability detection correctness. Factual CVE explanations, multi-paragraph coherence, and remediation depth were all outside the reward signal. When you optimize a 1.68B parameter model hard for a narrow classification task, everything else can degrade—the model doesn’t have enough capacity to maintain multiple capabilities simultaneously.
RL improved reward-aligned vulnerability scoring behavior and degraded open-ended security explanation quality. The model stayed fluent. The fluency masked factual errors. For accurate CVE-specific workflows, you’d need retrieval-augmented generation against authoritative sources (NVD, vendor advisories, CISA KEV).
2) Binary reward granularity
A reward of 1.0 or 0.0 gives clear signal for classification outcomes and weak signal for everything else. There’s no partial credit for identifying the right vulnerability class while misattributing the affected component. There’s no penalty for hallucinated details as long as the final #### Yes or #### No is correct.
Richer reward shaping—partial credit for correct reasoning steps, penalties for fabricated specifics—would give the model more useful gradient signal. Designing and validating those reward functions is its own engineering challenge.
3) Data shape and multi-turn balance
The security datasets were overwhelmingly single-turn structured Q&A. The multi-turn signal came from SmolTalk (general conversation, not security-specific) and those five fallback identity conversations. Direct security answers improved. Good multi-turn behavior had almost no training pressure behind it.
A model trained mostly on single-turn exchanges doesn’t learn when to ask clarifying questions, how to maintain context across follow-ups, or how to gracefully handle ambiguous prompts. Those are the exact capabilities an analyst-facing tool needs.
The Checkpoint Tradeoff
The run produced a practical split between two usable checkpoints:
| Checkpoint | Step | VulnDetection | Best For |
|---|---|---|---|
| SFT | 682 | 50.91% | General security Q&A, threat modeling, explanatory prompts |
| RL | 464 | 49.95% | Narrow vulnerability detection classification |
The evaluation summary from the training report tells the fuller story:
| Metric | SFT | RL |
|---|---|---|
| ARC-Easy | 0.2487 | 0.2433 |
| ARC-Challenge | 0.2338 | 0.2304 |
| MMLU | 0.2354 | 0.2368 |
| GSM8K | 0.0008 | 0.0083 |
| HumanEval | 0.0793 | 0.0000 |
| VulnDetection | 0.5091 | 0.4995 |
RL slightly degraded general reasoning benchmarks (ARC, HumanEval) and barely moved VulnDetection. The most striking number is HumanEval dropping from 7.93% to 0.00%—the RL objective pushed the model away from code generation entirely. Narrow RL optimization caused collateral capability loss.
For practical use, the SFT checkpoint is the better starting point for interactive security work. The RL checkpoint should only be used for the specific binary classification task it was trained for.
Closing Notes
This run succeeded as an engineering exercise. The full pipeline—non-spot provisioning, base pretraining, SFT on a mixed security corpus, RL with a binary vulnerability reward, evaluation, and artifact export—ran end-to-end in about 6 hours on 8x H100s for around $150. Both checkpoints were generated and usable for local inference.
It also made the next set of technical priorities very concrete:
- Retrieval grounding for CVE-specific factual prompts. The model’s own weights can’t reliably store and retrieve detailed vulnerability attributions, especially at 1.68B parameters. RAG against NVD or vendor advisories is the obvious fix.
- Richer reward shaping beyond binary correctness. Partial credit for reasoning quality, penalties for fabricated specifics, and multi-axis evaluation (classification accuracy + explanation quality + factual grounding) would give RL more useful signal.
- Explicit eval suites for repetition detection and open-ended security explanation quality. The current VulnDetection benchmark only measures binary classification. It doesn’t catch the repetitive
### Threat Modelloops or the confident hallucinations—exactly the failure modes that matter most for analyst-facing use. - Multi-turn identity data at scale. Five fallback conversations isn’t enough. Generating hundreds of multi-turn security dialogues with persona consistency would strengthen the model’s weakest behavioral axis.
Those changes would move the project from a strong demo pipeline toward something an analyst could actually rely on. But that’s the next run.
Let me know what I got wrong and where I lost the plot. I’m just diving into these things to see how they work.