Argus: Agentic Threat Modeling with the Claude Agent SDK
How Argus wraps Trail of Bits' skills and the advisor/executor pattern into an end-to-end threat-modeling pipeline
Disclaimer: This post is for educational purposes and authorized security testing only. Only use these techniques against systems you own or have explicit permission to assess, and do not violate laws, contracts, or terms of service. The setup described here runs through Claude Code with a user-authenticated Max/Claude environment, which is fine for research and personal projects. For production or team builds, switch to the Claude API directly — that is what the usage terms and capacity are designed for.
Table of Contents
- Introduction
- What Argus Does
- The Pipeline
- Cerbero, Briefly
- Pivoting to Skills
- Executor and Advisor
- Running It Against LegalCaseFlow
- Results
- How It All Relates
- References
Introduction
TL;DR — Argus is an agentic threat-modeling tool. Many specialized agents examine a target from different angles, a small number of advisor agents critique the high-leverage phases, and the pipeline produces a prioritized
threats.jsonplus a narrative report. Trail of Bits’ Claude Code skills do most of the heavy lifting, and the Claude Agent SDK lets agents call them directly.
In the previous post I wrote up the building blocks I keep returning to when designing agentic systems. Argus is the project I had been sitting on while writing that — a threat-modeling pipeline named for the hundred-eyed guardian of Greek myth, where each “eye” is a specialized agent watching the target from a different angle.
Argus takes a repository (and optionally design docs) and produces a prioritized, machine-readable list of threats worth probing, plus a human-readable report wrapping them.
This design is not fixed and will keep changing as the landscape evolves — which, at the rate things are moving, means about daily. The goal of the write-up is to hand over ideas you can adapt, not a finished recipe. I have also run Argus against a handful of my own projects beyond the deliberately vulnerable target in this post, and the shape has held up across them so far.
▸ View the Argus infographic — a one-page visual walkthrough of the pipeline, agents, and outputs.
What Argus Does
You hand Argus an EngagementSpec manifest pointing at one or more repositories (and optional design docs). It writes everything under ~/.argus/engagements/<id>/:
1
2
3
4
5
6
7
8
manifest.resolved.json
events.jsonl
status.json
phase-status.json
phases/01-ingest/ ... phases/08-report/
threats/<threat-id>.json
threats.json
report.md
Files are the source of truth. The CLI is a thin client over a headless service layer, so a future HTTP API or UI can share the same engagement state with no rewrites.
The primary deliverable is threats.json. Each entry is a structured record — entry point, ordered attack path, grounded evidence, reachability, priority, and a few other fields. A full example appears in the Results section below.
Controversial take, but there is no STRIDE anywhere in the pipeline. Argus is framework-agnostic on purpose. I wanted judgment over taxonomy and a short list of things worth attacking over a long list of categories checked.
The Pipeline
Linear phases with two explicit concurrent fan-outs:
ingest— parse the manifest, resolve paths and refs, clone repos, extract PDF text, run a secret scan. Emitsmanifest.resolved.json.audit-context— build deep per-repository context. Invokesaudit-context-building:audit-context-building.- Concurrent fan-out (join before phase 4):
git-themes— runsdifferential-review:differential-reviewwhen a base ref is declared. Skipped cleanly otherwise.input-discovery—static-analysis:semgrepplus code-grounded reasoning to surface user-controlled sources.arch-doc-ingest— extract stated assets, actors, boundaries, and deployment facts from design docs.
taint-trace— fan-out per discovered source. Each source gets traced to its terminal sink withstatic-analysis:semgrep,static-analysis:codeql, andstatic-analysis:sarif-parsingas applicable.asset-actor-boundary— unify evidence from phases 2–3 into a single components/assets/actors/boundaries model.threat-enumeration— fan-out per component. Each component-scoped enumerator produces concrete source-to-sink threats.prioritize— a single advisor-shaped phase that reads the full threat list and assignspriority+priority_rationale. Reachability is a dominant input signal.report— narrativereport.mdwrapping the prioritizedthreats.json.
Out of band, argus probe <engagement-id> opens a REPL backed by the on-disk engagement. Deterministic commands update threat state; free-form input goes to a read-only probe agent and appends to phases/probe/transcript.md. Fresh session per invocation so scripted and concurrent clients stay safe.
Each phase tolerates one retry on agent error and one revision-request loop on schema failure. Empty artifacts are marked skipped with a reason. Persistent failures degrade downstream phases and complete the engagement with status: partial.
Cerbero, Briefly
Argus is built on Cerbero, a TypeScript agent harness I introduced in the Cassian post. Cerbero is the orchestration layer that sits between your agent definitions and the Claude Agent SDK. It owns agent registration, tool routing, permissions, session state, the event bus, and the runner that drives each conversation, so every agentic system I build starts with a manifest of agents and a pipeline rather than raw SDK wiring.
Argus runs through Cerbero’s claude-agent-sdk provider, which uses the Claude Code surface and the user’s Claude-authenticated environment rather than constructing raw Messages API requests. That distinction matters for the advisor section below — it is the reason Argus implements the advisor pattern itself instead of using Anthropic’s API-native Advisor tool.
Argus wires itself into Cerbero in one place — a thin backend that creates the harness, registers every Argus .agent.md file as a Cerbero agent, and exposes a run(agent, context) function:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
const harnessConfig = HarnessConfigSchema.parse({
defaultModel: { providerID, modelID },
providers: [],
agents: {},
permission: [],
oracle: { maxConcurrentAgents: 16, maxToolCallsPerRun: 200, persistEvents: false },
approval: { defaultPolicy: "allow", leaseDurations: {}, toolPolicies: {} },
plugins: [],
pool: { maxConcurrent: 16 },
resilience: {},
hotReload: false,
promptDirs: [],
})
const harness = await createHarness(harnessConfig, { inMemory: options.inMemory ?? true })
CerebroAgent.clear()
await harness.init()
CerebroAgent.register(
Object.fromEntries(
registry.agents.map((agent) => [
agent.info.id,
toCerebroAgentInfo(agent, agentRegistrationOptions(options, cwd, permissionMode)),
]),
),
)
Each agent is defined as an Argus .agent.md file with JSON frontmatter. Argus’s loader accepts shorthands like mode: "advisor", model: "claude-sonnet-4-6", and permission: "read-only" that are not raw Cerbero schema values. toCerebroAgentInfo then normalizes those shorthands into a valid Cerbero Agent.Info before registration, copying Claude Agent SDK options such as tools and allowedTools through as-is while transforming the Argus-specific fields:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
function normalizeSdkOptions(agent: AgentDefinition, options: CerebroAgentOptions) {
const sdkOptions: AgentSdkOptions = { ...agent.info.options }
if (agent.info.tools !== undefined && sdkOptions.tools === undefined) {
sdkOptions.tools = agent.info.tools // e.g. { type: "preset", preset: "claude_code" }
}
if (agent.info.allowedTools !== undefined && sdkOptions.allowedTools === undefined) {
sdkOptions.allowedTools = agent.info.allowedTools // e.g. ["Skill", "Read", "Bash", "Grep", "Glob"]
}
if (options.cwd && sdkOptions.cwd === undefined) sdkOptions.cwd = options.cwd
if (sdkOptions.settingSources === undefined) sdkOptions.settingSources = ["user"]
if (sdkOptions.permissionMode === undefined) {
sdkOptions.permissionMode = options.permissionMode ?? "bypassPermissions"
}
if (sdkOptions.maxTurns === undefined) sdkOptions.maxTurns = agent.info.steps
return sdkOptions
}
Two of those fields — settingSources: ["user"] and permissionMode: "bypassPermissions" — are Argus-backend defaults, not generic Cerbero defaults. A different backend on the same harness could choose differently.
When the runner wants to drive an agent, it just creates a message and hands it off. Bus events carry tool-call signals back so the runtime can log them:
1
2
3
4
5
6
7
8
9
10
11
const message = Message.create({
sessionID: state.sessionId,
role: "user",
agentID: agent.info.id,
parts: [{ type: "text", content: formatAgentContext(context) }],
})
const result = await state.harness.runner.run({
agent: agent.info.id,
sessionID: state.sessionId,
messages: [message],
})
That is the full footprint. Everything else — retries, permissions, tool dispatch, bus events — is Cerbero doing its job underneath. One implementation detail worth flagging: the Argus backend initializes Cerbero with inMemory: true by default, so a normal Argus run keeps the Cerbero session in memory rather than persisting it to disk. Engagement artifacts are still on disk under ~/.argus/engagements/<id>/ — that is the source of truth — but Cerbero’s own session state for a single run is ephemeral unless a caller opts in.
Pivoting to Skills
This is the piece I wanted to highlight. Claude Code exposes a Skill tool. The Claude Agent SDK, when you configure an agent with the claude_code tools preset and declare Skill in allowedTools, gives that agent the same Skill tool.
Trail of Bits ships several Claude Code skills I rely on here:
audit-context-building:audit-context-building— deep architectural context before vulnerability hunting.differential-review:differential-review— security-focused review of diffs, with blast radius and regression checks.static-analysis:semgrep,static-analysis:codeql,static-analysis:sarif-parsing— run scans and reason over their SARIF output.
Argus agents do not run any of these themselves. They declare which skills they are allowed to call, ask for them by name in the prompt, and let the skill decide applicability.
The audit-context-builder agent — phase 2 — is the shortest example. Here is the Argus agent file, before Argus normalizes it into Cerbero’s schema:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
---
{
"id": "audit-context-builder",
"name": "Audit Context Builder",
"mode": "primary",
"model": "claude-sonnet-4-6",
"permission": "read-only",
"steps": 60,
"options": {},
"tools": { "type": "preset", "preset": "claude_code" },
"allowedTools": ["Skill", "Read", "Bash", "Grep", "Glob"]
}
---
Build audit context for each repository in the resolved manifest.
Invoke the `audit-context-building:audit-context-building` skill through the
Skill tool. Use repository paths, declared scope, base/head refs, docs, and
operator context from the engagement state. Ground the output in files and
directories that exist in the target.
Keep this phase in pure context mode. Do not turn the audit context into
vulnerability findings, proof-of-concept reasoning, fixes, or severity ratings.
Two fields do all the work. "tools": { "type": "preset", "preset": "claude_code" } tells the SDK to attach the Claude Code tool surface, including Skill. "allowedTools": ["Skill", "Read", "Bash", "Grep", "Glob"] pre-approves the Claude Code built-ins the agent may call; Cerbero may also merge in harness-exposed MCP tool names for bridged custom tools at runtime. The prompt then says what skill to invoke and how to constrain its output.
The diff-reviewer agent is the same pattern wrapped around differential-review:differential-review. The input-discoverer uses static-analysis:semgrep as a first-pass source discovery aid and reasons over the results to prune false positives. The taint-tracer uses all three static-analysis skills as applicable and falls back to manual, code-grounded tracing when a scanner is unsupported or low-signal:
1
2
3
4
5
6
7
8
9
10
11
12
13
Use these static-analysis skills through the Skill tool as applicable:
- `static-analysis:semgrep`
- `static-analysis:codeql`
- `static-analysis:sarif-parsing`
Let the skills determine scanner applicability, language coverage, scan mode,
database quality, and result quality. ...
If a scanner is unavailable, not applicable, or low-signal for this source,
state that limitation in `summary` and continue with manual, code-grounded
tracing. Do not fabricate scanner evidence or treat zero findings as proof that
the source is safe.
The same two frontmatter fields (tools + allowedTools) flow through toCerebroAgentInfo into @anthropic-ai/claude-agent-sdk unchanged. The SDK handles everything from there.
Executor and Advisor
Anthropic wrote a useful post on the advisor strategy: a primary agent does the work, a second agent with a different vantage point critiques it, and the primary gets one shot to revise based on that critique.
Argus adopts the executor/advisor pattern from that post. A quick disambiguation first: Anthropic also ships a beta API-native Advisor tool (advisor_20260301) on the Claude Messages API that implements a single-request version of the same idea on the server side. Argus does not use that tool. Because this setup runs through Claude Code with a user-authenticated environment rather than raw Messages API calls, Argus realizes the pattern explicitly in pipeline code with separate advisor agent invocations through the Claude Agent SDK path.
Argus applies advisors selectively, only to the phases where judgment errors are expensive and easy to miss. Most phases run a single executor. Advisors attach to three of them:
input-discovery-advisor— critiques the source list before it becomes input to phase 4.taint-trace-advisor— catches missed hops, ungrounded claims, impossible flows, unreachable sinks.threat-enumeration-advisor— reviews candidate threats component-by-component.
prioritizer is itself an advisor-shaped phase. It reads the full threat list and assigns labels in one pass.
The advisor reads the executor’s artifact, writes critique.md and a revision_requests.json, and returns structured revision requests. Those requests can trigger at most one executor re-run. The pipeline code enforces that bound so a disagreeing advisor cannot loop the phase indefinitely.
An abridged version of the input-discovery phase, showing what “executor + advisor” looks like in practice:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
async function runInputDiscoveryWithAdvisor(
store: EngagementStore,
engagement: Engagement,
runtime: Runtime,
context: Phase3Context,
): Promise<void> {
// 1. Executor: discover sources.
const initial = await runtime.runJSON("input-discoverer", context, InputDiscoverySchema)
if (initial.sources.length === 0) {
await writeInputDiscovery(store, engagement, initial)
throw new PhaseSkippedError("input-discoverer returned no sources")
}
await writeInputDiscovery(store, engagement, initial)
// 2. Advisor: critique the executor's artifact, emit bounded revision requests.
const advisor = await runtime.runJSON(
"input-discovery-advisor",
{ ...context, inputDiscovery: initial },
InputDiscoveryAdvisorSchema,
)
await store.writeArtifact(engagement.id, "phases/03-input-discovery/critique.md", advisor.critique)
await store.writeArtifact(
engagement.id,
"phases/03-input-discovery/revision_requests.json",
`${JSON.stringify(advisor.revision_requests, null, 2)}\n`,
)
if (advisor.revision_requests.length === 0) return
// 3. Executor reruns exactly once with the advisor's critique folded into context.
await store.appendEvent(engagement.id, {
event: "advisor.revision_requested",
advisor_id: "input-discovery-advisor",
agent_id: "input-discoverer",
request_count: advisor.revision_requests.length,
})
const rerun = await runtime.runJSON(
"input-discoverer",
{
...context,
previousInputDiscovery: initial,
revisionRequest: advisor.revision_requests.join("\n"),
},
InputDiscoverySchema,
)
await writeInputDiscovery(store, engagement, rerun)
}
A few things worth calling out. The advisor writes critique.md and revision_requests.json whether or not it asks for a rerun — the critique is useful evidence even when it is “looks fine.” The executor’s rerun context carries previousInputDiscovery and revisionRequest explicitly so the prompt can address the critique rather than regenerating from scratch. For this particular phase the input-discovery-advisor runs on claude-sonnet-4-6; the more judgment-heavy taint-trace-advisor, threat-enumeration-advisor, and prioritizer run on claude-opus-4-7. Most executors run on Sonnet, with the mechanical ingester dropping down to claude-haiku-4-5. The advisors that get Opus get it specifically because they are paid to disagree.
The advisor itself has no tools. It gets the executor’s artifact plus curated phase context — input-discovery-advisor receives { ...context, inputDiscovery: initial }, taint-trace-advisor receives { ...context, taintTraceResults: initial }, and threat-enumeration-advisor receives { ...context, candidateThreats: ... } — and returns structured JSON:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
---
{
"id": "taint-trace-advisor",
"name": "Taint Trace Advisor",
"mode": "advisor",
"model": "claude-opus-4-7",
"permission": "read-only",
"steps": 40,
"options": {}
}
---
Critique taint-trace results for missed hops, ungrounded claims, duplicate
paths, impossible flows, and unreachable terminal sinks.
Review all taint-trace results together with the audit context, git themes,
input-discovery source list, and architecture facts. Request a rerun only when
a specific source needs a bounded correction. The runner allows at most one
executor rerun, so keep each request precise.
To restate the earlier point: Argus does not use Anthropic’s API-native Advisor tool here. Advisors are registered as separate Argus/Cerbero agent invocations through the Claude Agent SDK path, and the executor/advisor behavior comes from how the pipeline code sequences those invocations.
Running It Against LegalCaseFlow
The live target for this run is LegalCaseFlow, a legal case-management SaaS I built as a deliberately vulnerable TypeScript monorepo: Express 5.1 API, React SPA, PostgreSQL 15, nginx, Docker Compose, an init container that seeds demo data. Roughly the shape of a real SaaS codebase, with realistic-looking vulnerabilities layered in.
The manifest is four lines:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
name: legalCTF Threat Model
repos:
- name: legalCTF
path: ./targets/legalCTF
head_ref: HEAD
security:
secret_policy:
- path: .env.example
kind: hard_excluded_path
decision: exclude
- path: apps/api/src/utils/crypto.ts
kind: generic_high_entropy
decision: redact
Phase 3 shows the executor/advisor loop running live. The input-discoverer runs once, the advisor weighs in, and the executor reruns with the critique:
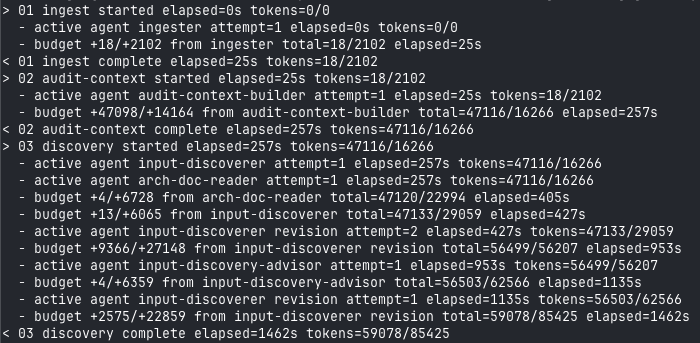 Phase 3 fan-out:
Phase 3 fan-out: input-discoverer runs, input-discovery-advisor critiques, then the executor reruns with revision context. diff-reviewer is skipped here because the manifest has no base ref.
Phase 4 fans out per discovered source — 59 of them for this target. Each gets its own taint-tracer invocation running the static-analysis skills and building source-to-sink paths:
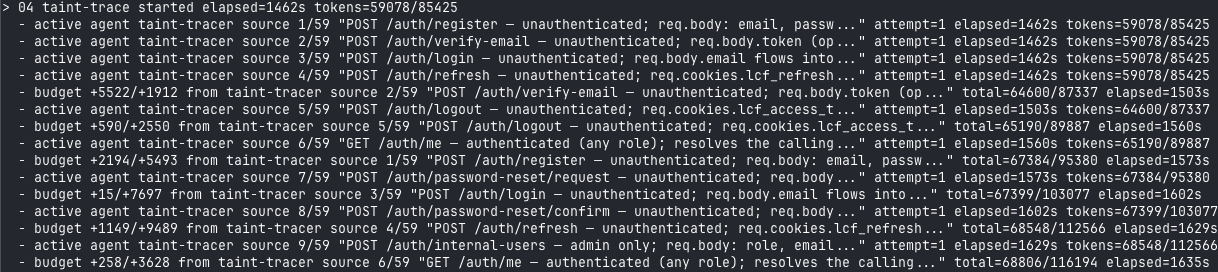 Phase 4 taint-trace fan-out across 59 user-controlled sources. Each source becomes an independent agent invocation with its own token budget.
Phase 4 taint-trace fan-out across 59 user-controlled sources. Each source becomes an independent agent invocation with its own token budget.
Phase 6 fans out per component identified by the boundary modeler — 19 components here, each with its own threat-enumerator call:
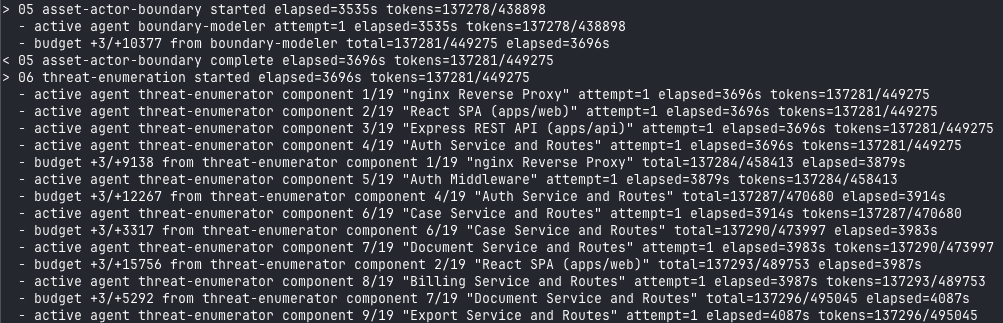 Phase 6 threat-enumeration fan-out across 19 components. The advisor runs once over all candidates and requests bounded reruns where needed.
Phase 6 threat-enumeration fan-out across 19 components. The advisor runs once over all candidates and requests bounded reruns where needed.
That observability layer is not a debugging afterthought. Structured events.jsonl plus a live tree in the terminal is how I actually catch when a phase is drifting, when a model is under-invoking a skill, or when an advisor is looping requests. I covered why this matters in the building blocks post.
Results
The full run produced 64 raw threat records from the LegalCaseFlow codebase.
| Priority | Count |
|---|---|
| Critical | 12 |
| High | 27 |
| Medium | 24 |
| Low | 1 |
| Total | 64 |
Total token spend: ~137K input, ~680K output. One run, eight phases, 19 components, 59 taint sources, one executor rerun per advised phase.
The raw count needs context. The threat-enumeration-advisor correctly flagged that the list was over-complete: several findings repeated across component anchors, especially token theft, case-search SQLi, User-Agent audit poisoning, admin role promotion, and refresh-token persistence. Argus preserved all 64 source-grounded records, but after human triage they collapse to roughly 22 distinct probe themes: 4 critical, about 11 high, about 6 medium, and 1 low/recon item.
The next iteration should therefore add a canonicalization phase between threat-enumeration and prioritize — merging threats by root cause, entry point, sink, impacted asset, and remediation, then attaching the duplicate component framings as supporting evidence. I could have run the triage myself and shown you only the cleaned-up 22, but I wanted to include the raw results so the process is visible. Useful output is not the same thing as trustworthy output, and the only way to catch the gap is to read what actually landed.
One threat record in full, exactly as it landed in threats.json:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
{
"id": "T-sql-injection-at-login-via-unparameterized-email",
"fingerprint": "fp-v1-...",
"title": "Login endpoint interpolates email directly into SQL WHERE clause",
"component": "Express REST API (apps/api)",
"entry_point": "POST /auth/login",
"attack_path": [
"req.body.email is read at auth.routes.ts without parameterized binding.",
"The value is string-interpolated into a WHERE clause in auth.service.ts:165-190.",
"The query executes against PostgreSQL with no row-level security."
],
"preconditions": ["Route is reachable without authentication."],
"asset_at_risk": "All user credentials and session data",
"trust_boundary": "Internet → Express REST API → PostgreSQL",
"reachability": "internet",
"evidence": [
{ "ref": "apps/api/src/services/auth.service.ts:165-190", "detail": "..." }
],
"probe_hints": ["Send a single quote in the email field and observe SQL error behavior."],
"priority": "critical",
"priority_rationale": "Internet-reachable, unauthenticated, direct path to full credential dump.",
"confidence": "high",
"status": "open"
}
That shape is the part I care about. Every finding has a concrete entry point, source-to-sink path, preconditions, asset, trust boundary, evidence, probe hints, confidence, and status — grounded enough for a human operator to probe without going back to the code to reconstruct context.
How It All Relates
Argus is one piece of a larger offensive-to-defensive loop I have been assembling. Start with Argus to produce the threat model, feed that prioritized backlog to ODYSSEUS to run the actual pentest, let builders fix the issues those exploits surface, then hand the remediation PRs to Cassian to verify the fixes actually close the threats and have not regressed anything else. Threat model, test, fix, verify, all as agentic stages you can wire into a CI/CD pipeline rather than a calendar item that happens twice a year.
The gotcha anyone who has done offensive work already knows is the test environment. Real pentests need a realistic environment with seeded data, live credentials, and the correct integrations stood up. Today that is mostly manual and it slows everything down. There is a fix for that involving spinning environments on the fly by mocking the right components, and it is worth its own post. I am also not at the point where I trust an LLM to fix the issues these tools discover, so the “builder” step in the loop above is still a human. That may change, but I am not rushing to find out.
References
- Trail of Bits Claude Code skills used throughout the pipeline:
audit-context-buildingstatic-analysis(semgrep, codeql, sarif-parsing)differential-review
- Anthropic — The Advisor Strategy